Understanding HTTP Response Codes – What Are They & What Do They Mean?
Posted: September 18th, 2024
HTTP Status Codes
In the world of web development, clear communication between a client (like your browser) and a server (where websites live) is crucial.
Every time you click a link, submit a form, or make an API call, a silent conversation happens behind the scenes. This conversation is made up of requests and responses that are governed by a language of codes—HTTP status codes.
These three-digit codes are the unsung heroes of the internet, signalling whether a request was successful, if something needs attention, or if something has gone wrong. From the familiar 404 Not Found to the more obscure 418 I’m a Teapot, each code has a specific role in guiding web interactions.
Ultimately, they determine what you see next when you are navigating around the web.
Why are Response Codes Important?
HTTP response codes might seem like just a series of numbers, but they play a vital role in how the web functions.
These codes are essential for maintaining smooth communication between a client (like a web browser or mobile app) and a server (where websites and applications are hosted).

Understanding why these codes are important can help both developers and everyday users understand web interactions.
Communication Clarity
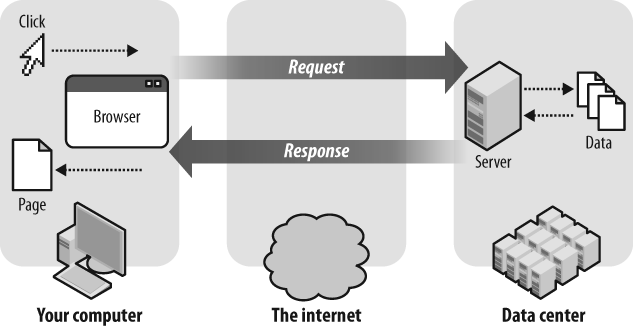
In its simplest terms, the internet is a huge network of requests and responses.
When you enter a URL or click a link, your browser sends a request to a server asking for information. The server then responds with an HTTP status code that tells the browser what happened with that request.
Source: Victor Ohachor via LinkedIn
Did it succeed? Was the page moved? Is there a problem? These codes ensure that both the client and server are on the same page, enabling a seamless experience.
For developers, these codes provide clear signals on how their web applications are performing. For instance, a 200 OK tells them that everything is working as expected, while a 500 Internal Server Error alerts them to something going wrong on the server side.
Without these status codes, diagnosing and resolving issues would be like trying to fix a car without any warning lights.
User Experience
From a user perspective, HTTP response codes directly impact how we experience the web.
Imagine clicking a link and seeing a 404 Not Found error instead of the page you were expecting.
It’s a clear indicator that something went wrong, whether the page was moved, deleted, or the URL was mistyped. While it might be frustrating, this error code prevents the browser from displaying a blank page or crashing altogether.
Properly handled response codes can also lead to better user experiences. For example, when a page is moved, a 301 Moved Permanently code can redirect users to the new page without them even realising there was a change.
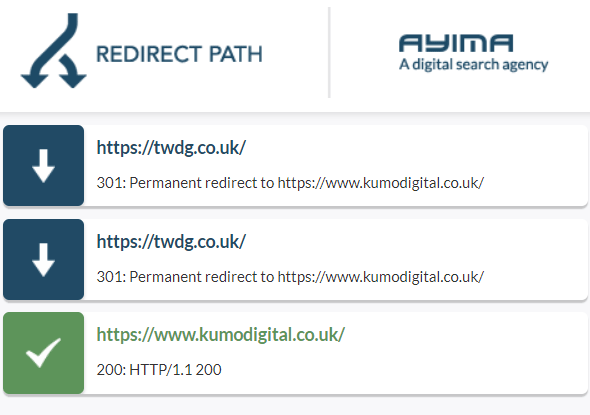
This not only preserves the user journey but it also ensures that search engines correctly update their indexes.
Search Engine Optimisation (SEO)
For website owners and digital marketers, HTTP status codes play a critical role in Search Engine Optimisation (SEO).
Search engines like Google use these codes to understand the structure of a website. If a page returns a 200 OK, it signals to search engines that the content is available and can be indexed.
However, if a page returns a 404 Not Found or a 410 Gone, search engines know to remove that page from their indexes, as it’s no longer available.

Redirects, particularly 301 Moved Permanently, are also vital for SEO. When you change a URL, using a 301 redirect may help to ensure that any ranking power or authority from the old URL is transferred to the new one. This, in turn, can prevent the loss of traffic and rankings, which may have otherwise occurred if the change wasn’t properly communicated to search engines.
Security Implications
HTTP status codes also play a role in the security of web applications. For instance, a 403 Forbidden status code is used to prevent unauthorised access to certain parts of a website or application.
It indicates that while the server understood the request, it refuses to authorise it, therefore protecting sensitive information from unauthorised users.
Additionally, response codes like 401 Unauthorised are crucial in enforcing authentication protocols. When a resource requires proper credentials, this code ensures that only authenticated users gain access. This layer of security is fundamental in protecting user data and maintaining trust.
Efficient Resource Management
On a more technical level, HTTP response codes help manage the resources of both clients and servers efficiently.
For example, a 304 Not Modified response indicates that the requested resource hasn’t changed since the last request. This allows the browser to use a cached version of the resource instead of downloading it again, therefore saving bandwidth and speeding up the loading process.
This efficiency is critical for optimising the performance of websites, especially those with high traffic volumes.
Legal and Compliance Reasons
In some cases, response codes are used to comply with legal requirements. The 451 Unavailable For Legal Reasons status code, for example, indicates that access to the requested resource has been blocked due to legal restrictions, such as a court order or government regulation.

This transparency is essential for both users and site administrators, ensuring that access restrictions are clearly communicated and understood.
Common HTTP Response Codes and Their Impact on Users and Crawlers
Some HTTPs response codes are more common than others. Again, when you browse the web, every interaction between your browser and a website is governed by HTTP response codes.
These codes also play a significant role in how search engines like Google index and rank your site.
200 OK
What It Means: This is the ideal response code. It means that the request was successful, and the server is returning the requested resource, such as a webpage, image, or file.
Impact on Users: For users, a 200 OK response means the webpage loads smoothly without issues. They can view the content they requested without any interruptions.
Impact on Crawlers: Search engine crawlers, like Googlebot, view a 200 OK as a sign that the page is available and working correctly. This allows the page to be indexed and potentially shown in search results. A site with mostly 200 OK responses is more likely to be well-indexed and ranked by search engines.
301 Moved Permanently
What It Means: A 301 response indicates that the requested resource has been permanently moved to a new URL. The server provides the new URL, and both users and crawlers are redirected to this new location.
Impact on Users: For users, a 301 redirect means they are automatically sent to the new page without realising it. It preserves the user experience by ensuring that they reach the correct content, even if the URL has changed.
Impact on Crawlers: For crawlers, a 301 redirect is crucial for SEO. It signals that the content has moved permanently, so the search engine may choose to transfer authority from the old URL to the new one.
Proper use of 301 redirects have often helped maintain search rankings and ensure that the new URL is indexed correctly.
This is often disputed, however, especially where redirects have been implemented that don’t really mimic the purpose of the original URL.
302 Found (Temporary Redirect)
What It Means: A 302 response code indicates that the resource has been temporarily moved to a different URL. Unlike a 301 redirect, this move is not permanent, and the original URL should still be used for future requests.
Impact on Users: Users are redirected to the temporary URL, and their experience remains smooth. However, if the 302 redirect is used incorrectly, it can cause confusion, especially if users are expecting a permanent move.
Impact on Crawlers: For search engines, a 302 redirect suggests that the move is only temporary, so the original URL should still be indexed rather than the new one. This can be problematic if you intended the move to be permanent but used a 302 instead of a 301, as it may not pass on authority to the new page.
404 Not Found
What It Means: A 404 error occurs when the server cannot find the requested resource. This usually happens if the page has been deleted or the URL is incorrect.
Impact on Users: Encountering a 404 error can be frustrating for users, as it means the page they were trying to access is not available. This can lead to a poor user experience, especially if the user cannot find what they were looking for.
This is the main reason the majority of sites have dedicated 404 pages, designed to keep users on the site in some capacity.
Impact on Crawlers: For crawlers, frequent 404 errors can be a red flag. If Googlebot finds many 404s on your site, it could affect your site’s SEO negatively. This is because it suggests poor site maintenance or outdated content. However, having a few 404s is normal, especially for content that has been intentionally removed, such as discontinued products or categories.
500 Internal Server Error
What It Means: A 500 error indicates a problem on the server that prevented it from fulfilling the request. The issue could be anything from a misconfiguration to a more severe server malfunction.
Impact on Users: Users encountering a 500 error are unable to access the content they were looking for, leading to frustration. Unlike a 404, which suggests a missing page, a 500 error indicates a deeper problem that often needs to be resolved by the website’s technical team.
Impact on Crawlers: Search engine crawlers may temporarily avoid indexing pages that return a 500 error. If the problem persists, it can harm your site’s search rankings, as search engines may consider the site unreliable or poorly maintained.
503 Service Unavailable
What It Means: A 503 error means that the server is currently unable to handle the request, often due to being overloaded or undergoing maintenance. The server should include a “Retry-After” header to indicate when the service will be available again.
Impact on Users: Users may see a 503 error if the website is down for maintenance or temporarily overloaded. While this can be inconvenient, it is often a short-term issue.
Impact on Crawlers: For crawlers, a 503 error signals that the site is temporarily unavailable but not permanently down. Search engines typically come back later to try indexing the page again. Regular 503 errors, however, can lead to reduced crawl rates and impact SEO if they persist over time.
Google Search Console and Crawl Reports
For website owners and SEO professionals, monitoring HTTP status codes is crucial for maintaining a healthy website. Google Search Console (GSC) is an invaluable tool in this regard.
GSC provides detailed reports on how Google’s crawlers interact with your website, including the HTTP status codes they encounter. These insights are essential for identifying and resolving issues that could affect your website’s performance in search results.
Crawl Reports: Understanding Your Website’s Health
Google’s crawlers, often referred to as Googlebot, regularly visit websites to index their content. During these crawls, Googlebot encounters various HTTP status codes, and these are reported back in GSC. The Page Indexing Report in GSC offers a breakdown of how Googlebot has crawled your site and provides reports into the types of HTTP responses received.
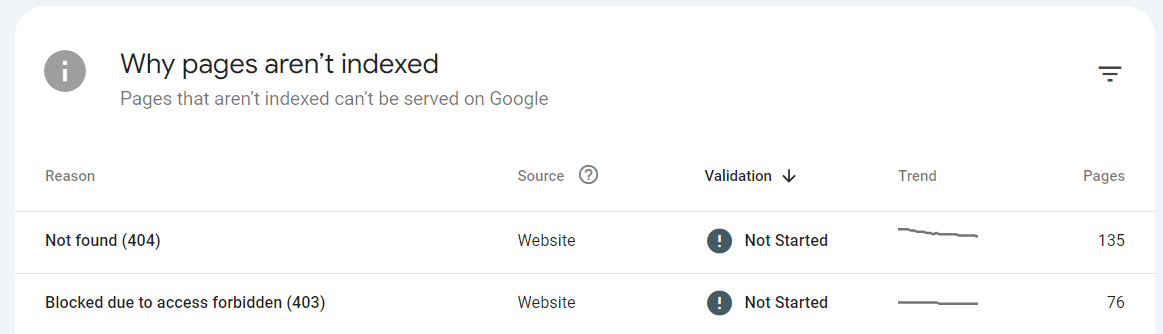
For example, if Googlebot frequently encounters 404 Not Found errors, this could indicate broken links or missing pages on your site.
These issues can negatively impact your site’s SEO by causing poor user experiences and reducing the overall quality of your site in Google’s eyes.
Actionable Insights for Status Codes
GSC doesn’t just report issues. It also provides actionable insights that help you address them. For instance:
- 404 Errors: If GSC reports numerous 404 errors, you might consider setting up 301 redirects to guide users and search engines from the old, non-existent URLs to the correct ones. This ensures that users and Googlebot can still access the desired content, preserving your site’s SEO value
- 500 Internal Server Errors: These errors indicate problems on the server that need immediate attention, as they can prevent Googlebot from accessing and indexing your site. GSC allows you to spot these errors quickly, therefore enabling you to investigate and resolve server issues before they impact your search rankings
- 301 and 302 Redirects: GSC can help you monitor how well your redirects are functioning. Proper use of 301 Moved Permanently redirects can preserve your site’s link equity, while 302 Found redirects, used incorrectly, might signal to Google that the move is temporary, potentially causing confusion and affecting your rankings
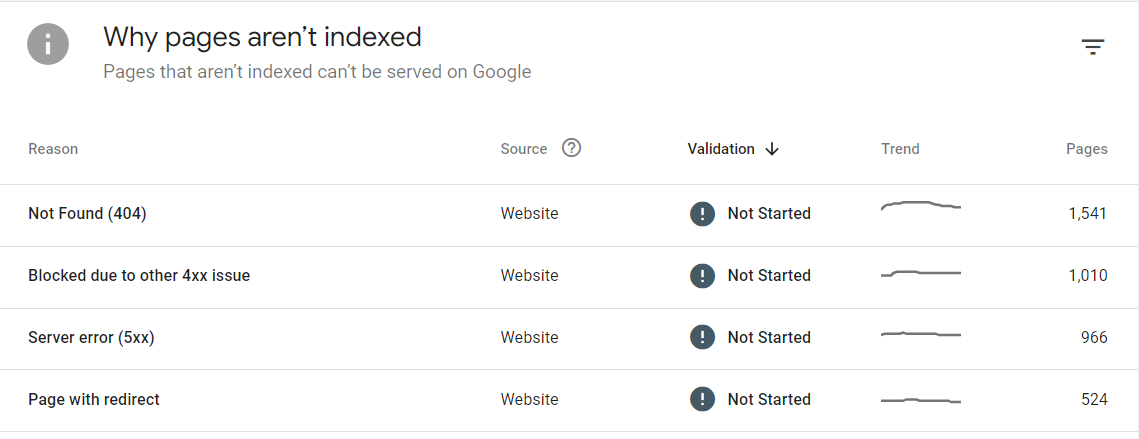
One of the key benefits of monitoring HTTP status codes via GSC is improving the efficiency of Googlebot’s crawls. By ensuring that your site returns the appropriate status codes—especially avoiding errors like 404s and 500s, you help Googlebot spend its crawl budget more effectively.
This means that Google can index more of your important content in a shorter amount of time, which can positively impact your site’s visibility in search results.
Inspecting Response Codes Using Server Logs
For anyone managing a website, server logs are a goldmine of information. They record every request made to your server, along with the corresponding HTTP response codes.
By inspecting these logs, you can gain deep insights into how your website is performing, identify potential issues and ensure that your visitors and search engine crawlers are getting the responses they need.
What Are Server Logs?
Server logs are files automatically created by your web server that track various details about incoming requests. Each entry in a server log typically includes:
- IP Address: The address of the client making the request
- Date and Time: When the request was made
- HTTP Method: The type of request (e.g., GET, POST)
- Requested URL: The resource being requested
- HTTP Status Code: The response code returned by the server
- User-Agent: Information about the client software, such as the browser or search engine crawler
These logs are usually stored in plain text files on the server and can be accessed via your hosting control panel, command line, or a log management tool.
Why Inspect Response Codes in Server Logs?
Inspecting the HTTP response codes in your server logs can help you:
- Identify Errors: Regularly checking for 404, 500, or other error codes can help you spot broken links, server issues, or other problems that could negatively impact user experience and SEO
- Monitor Redirects: Ensure that your 301 and 302 redirects are working as intended, preventing unnecessary detours that might confuse users or search engines
- Track Crawlers: Understand how search engine bots are interacting with your site by looking at the response codes they receive. This can help you identify if certain pages are being missed or crawled more frequently than necessary
- Optimise Site Performance: By analysing response codes like 200 OK and 304 Not Modified, you can gauge how efficiently your server is handling requests and if there are opportunities to improve load times or reduce server strain
How to Inspect Server Logs
Here are a few methods to access and inspect your server logs:
Accessing Logs via Hosting Control Panel: Most hosting providers offer easy access to server logs through their control panels (e.g., cPanel, Plesk). You can typically find logs under sections like “Raw Access” or “Error Logs.” From there, you can download and inspect these logs manually.
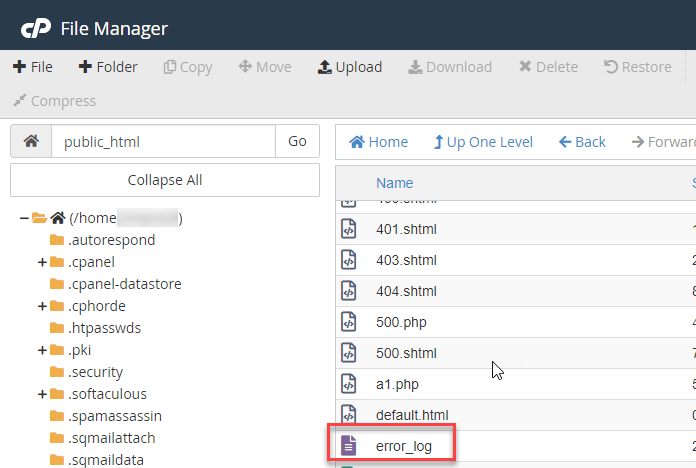
Using Command Line Tools: If you have access to your server via SSH, you can use command-line tools like tail, grep, or awk to filter and analyse log entries directly. For example:
tail -f /var/log/apache2/access.log allows you to view the latest log entries in real-time.
grep " 404 " /var/log/apache2/access.log will filter log entries that contain 404 status codes.
Utilising Log Management Tools: For larger websites, a log management tool like Loggly, Splunk, or ELK Stack can be invaluable. These tools offer advanced features like real-time monitoring, automatic alerts and visualisation, making it easier to spot trends and potential issues.
Analysing Logs: Once you’ve accessed your logs, you can start analysing them. Look for patterns in response codes, such as frequent 404 errors, or unusual spikes in 500 errors. Understanding these patterns can help you identify and fix problems before they impact users or your site’s SEO.
Turning Insights into Action
Inspecting server logs isn’t just about finding issues – it’s about taking action to improve your website. For example:
Fixing 404 Errors: If you spot repeated 404 errors for specific URLs, consider setting up 301 redirects to guide users and search engines to the correct content.
Resolving Server Issues: Frequent 500 errors might indicate server misconfigurations or resource limitations. Addressing these can improve site reliability and user satisfaction
Optimising for SEO: Ensuring that Googlebot encounters as few errors as possible helps maintain your site’s visibility in search results. Logs can also reveal if important pages are being missed by crawlers, prompting you to investigate and correct any underlying issues.
HTTP Response Code Best Practices
When working with HTTP response codes, using them correctly is essential for ensuring a smooth user experience and maintaining your website’s performance in search engine rankings.
Here are some best practices to keep in mind:
Use the Right Code for the Right Situation
It’s crucial to use the correct HTTP status code that accurately reflects the outcome of the request.
For instance, if a page is missing, the server should return a 404 Not Found code, not a 200 OK with a message saying “Page not found” displayed on the page.
Using the right status code helps browsers and search engines understand the situation and react appropriately.
Create Custom 404 Pages
When users land on a missing page, a custom 404 page can make all the difference. Instead of presenting a generic and unhelpful error message, you can design a 404 page that guides users back to your main site or suggests other useful content.
This keeps users engaged and reduces the chances of them leaving your site in frustration.
Monitor Regularly
Regularly monitoring your website’s response codes is key to catching issues before they affect users or search engine rankings.
Use tools like server logs, Google Search Console and automated monitoring tools to keep an eye on how your site is performing. This allows you to quickly address any errors or problems that arise.
Avoid Overusing Redirects
Redirects, especially 301 Moved Permanently redirects, are helpful for guiding users and search engines from old URLs to new ones.
However, overusing redirects, or setting up “redirect chains” (where one URL redirects to another, which then redirects to yet another), can slow down your website and confuse both users and search engine crawlers. In some cases, redirect loops can become a problem when not implemented correctly.

These loops have resources continually redirecting, often never eventually resolving.
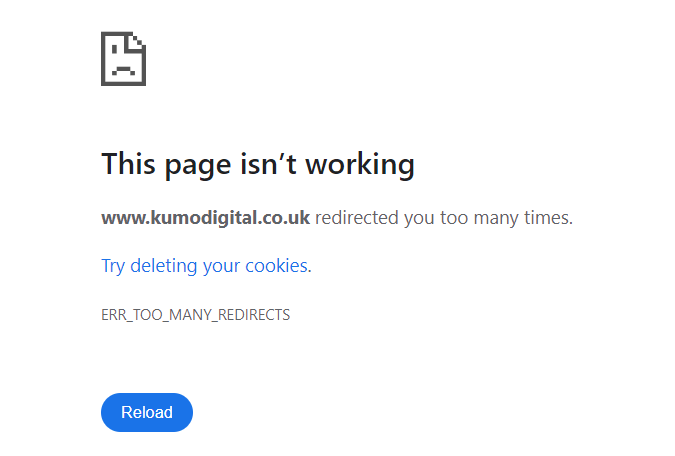
Aim to keep redirects to a minimum and ensure that they lead directly to the final destination without unnecessary steps.
The Role of HTTP/2 and HTTP/3 in Response Codes
As the web evolves, so do the protocols that govern how data is transmitted. HTTP/2 and HTTP/3 are the latest versions of the HTTP protocol, designed to make web browsing faster and more efficient.
Improvements in Efficiency
HTTP/2 and HTTP/3 introduce significant improvements in how requests and responses are handled.
While they still use the same fundamental HTTP status codes (like 200 OK and 404 Not Found), these newer protocols are designed to process requests more efficiently.
For example, HTTP/2 can handle multiple requests at once (a process known as multiplexing), reducing the time it takes for a page to load. This means that users and search engine crawlers can experience faster, more responsive websites.
Multiplexing and Response Codes
One of the key features of HTTP/2 is multiplexing, which allows multiple requests and responses to be processed simultaneously over a single connection.
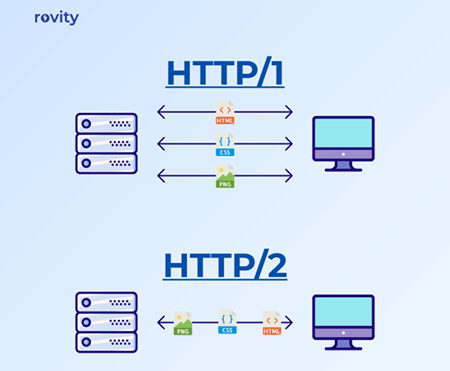
Source: Rovity.io
This reduces latency and can prevent issues where a slow-loading resource (like an image or script) delays the loading of the entire page.
While the HTTP response codes themselves remain unchanged, the way they are delivered is more efficient, leading to a better overall user experience and potentially faster indexing by search engines.
Security Considerations Related to Response Codes
HTTP response codes also play a role in your website’s security.
Preventing Information Leakage
Certain response codes, like 403 Forbidden or 401 Unauthorised, are used to protect sensitive areas of your website by restricting access. However, be mindful that returning too much information in these responses can unintentionally reveal details about your server or website structure, which could be exploited by attackers.
Ensure that your error messages are informative for legitimate users but do not disclose unnecessary technical details.
Handling DoS Attacks
Denial of Service (DoS) attacks aim to overwhelm a website with traffic, causing it to crash or become unavailable.
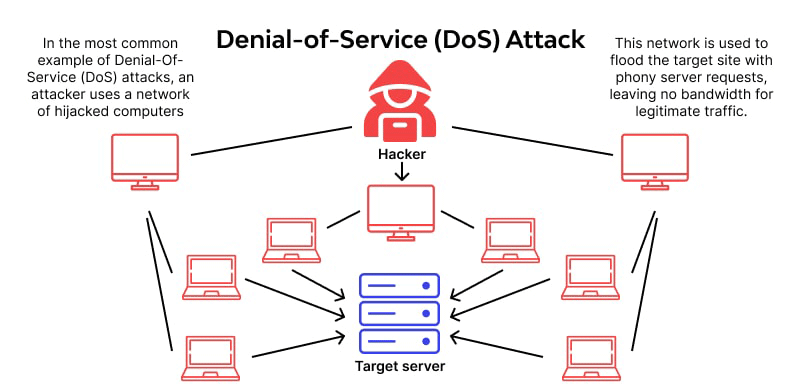
Source: wallarm.com
Monitoring your server logs for an unusual spike in 500-series errors, or even 503 Service Unavailable responses, can help you detect such attacks early.
Implementing security measures like rate limiting, firewalls and proper server configuration can help mitigate the impact of these attacks and maintain site availability.
More HTTPS Status Codes
1xx: Informational Responses
These codes indicate that the server has received the request and is continuing the process:
| Response Code | What It Means |
|---|---|
| 100 Continue | The server has received the initial part of the request, and the client should continue with the request |
| 101 Switching Protocols | The server agrees to switch protocols as requested by the client |
| 102 Processing (WebDAV) | Indicates that the server has received and is processing the request, but no response is available yet |
2xx: Success
These codes indicate that the client’s request was successfully received, understood and accepted:
| Response Code | What It Means |
|---|---|
| 200 OK | The request has succeeded. The meaning depends on the HTTP method (GET: resource retrieved, POST: resource created) |
| 201 Created | The request has been fulfilled and a new resource has been created as a result |
| 202 Accepted | The request has been accepted for processing, but the processing is not yet complete |
| 203 Non-Authoritative Information | The request was successful, but the returned meta-information is not from the original server |
| 204 No Content | The server successfully processed the request, but is not returning any content |
| 205 Reset Content | The server successfully processed the request, but asks the client to reset the document view |
| 206 Partial Content | The server is delivering only part of the resource due to a range header sent by the client |
3xx: Redirection
These codes indicate that further action is needed to complete the request:
| Response Code | What It Does |
|---|---|
| 300 Multiple Choices | The request has more than one possible response. The user or client should choose one of them |
| 301 Moved Permanently | The requested resource has been moved permanently to a new URL |
| 302 Found | The resource has been temporarily moved to a different URL, but future requests should still use the original URL |
| 303 See Other | The response can be found under a different URL and should be retrieved using a GET method |
| 304 Not Modified | The resource has not been modified since the last request. The client can use the cached version |
| 305 Use Proxy | The requested resource is only available through a proxy, the address for which is provided in the response |
| 307 Temporary Redirect | The resource has been temporarily moved to a different URL, and the client should use the original URL for future requests |
| 308 Permanent Redirect | Like 301, but the request method should not change |
4xx: Client Errors
These codes indicate that the client made an error, or the request cannot be fulfilled:
| Response Code | What It Means |
|---|---|
| 400 Bad Request | The server could not understand the request due to invalid syntax |
| 401 Unauthorised | The client must authenticate itself to get the requested response |
| 402 Payment Required | Reserved for future use; originally intended for digital payment systems |
| 403 Forbidden | The client does not have access rights to the content; the server is refusing to respond |
| 404 Not Found | The server cannot find the requested resource |
| 405 Method Not Allowed | The request method is known by the server but is not supported by the target resource |
| 406 Not Acceptable | The server cannot generate a response that the client can accept |
| 407 Proxy Authentication Required | Like 401, but authentication is required via a proxy |
| 408 Request Timeout | The server did not receive a complete request in time |
| 409 Conflict | The request could not be processed because of a conflict in the request |
| 410 Gone | The requested resource is no longer available and will not be available again |
| 411 Length Required | The server requires the request to have a valid Content-Length header |
| 412 Precondition Failed | One or more conditions in the request header fields evaluated as too false |
| 413 Payload Too Large | The request is larger than the server is willing or able to process |
| 414 URI Too Long | The URI requested by the client is longer than the server is willing to interpret |
| 415 Unsupported Media Type | The media format of the requested data is not supported by the server |
| 416 Range Not Satisfiable | The range specified by the Range header in the request cannot be fulfilled |
| 417 Expectation Failed | The server cannot meet the requirements of the Expect header |
| 418 I’m a Teapot | A humorous status code from an April Fools’ joke in 1998, indicating that the server refuses to brew coffee because it is a teapot |
| 421 Misdirected Request | The request was directed to a server that is not able to produce a response |
| 422 Unprocessable Entity (WebDAV) | The request was well-formed but could not be followed due to semantic errors |
| 423 Locked (WebDAV) | The resource that is being accessed is locked |
| 424 Failed Dependency (WebDAV) | The request failed because it depended on another request that also failed |
| 426 Upgrade Required | The client should switch to a different protocol |
| 428 Precondition Required | The server requires the request to be conditional |
| 429 Too Many Requests | The user has sent too many requests in a certain amount of time |
| 431 Request Header Fields Too Large | The server is unwilling to process the request because its header fields are too large |
| 451 Unavailable for Legal Reasons | The server is denying access to the resource because of a legal demand |
5xx: Server Errors
These codes indicate that the server failed to fulfil a valid request:
| Response Code | What It Means |
|---|---|
| 500 Internal Server Error | The server encountered an unexpected condition that prevented it from fulfilling the request |
| 501 Not Implemented | The server does not support the functionality required to fulfil the request |
| 502 Bad Gateway | The server, while acting as a gateway or proxy, received an invalid response from the upstream server |
| 503 Service Unavailable | The server is not ready to handle the request. Common reasons include being down for maintenance or being overloaded |
| 504 Gateway Timeout | The server, while acting as a gateway or proxy, did not receive a timely response from the upstream server |
| 505 HTTP Version Not Supported | The server does not support the HTTP protocol version used in the request |
| 506 Variant Also Negotiates | Transparent content negotiation for the request results in a circular reference |
| 507 Insufficient Storage (WebDAV) | The server is unable to store the representation needed to complete the request |
| 508 Loop Detected (WebDAV) | The server detected an infinite loop while processing a request |
| 510 Not Extended | Further extensions to the request are required for the server to fulfil it |
| 511 Network Authentication Required | The client needs to authenticate to gain network access |
Find Out More
To learn more about HTTP response codes, you can explore various online resources, including:
Mozilla Developer Network (MDN): The MDN Web Docs provide comprehensive and beginner-friendly explanations of HTTP status codes, complete with examples.
Google Search Central: Google’s own documentation offers advice on handling response codes, especially in the context of SEO, making it a valuable resource for webmasters
Author Biography
Tieece
As an SEO Executive at Kumo since 2015, Tieece oversees the planning and implementation of digital marketing campaigns for a number of clients in varying industries.
When he's not crawling sites or checking Analytics data, you'll often find him (badly) singing along to music that nobody else in the office is in to.
Tieece holds a number of digital marketing accreditations including Google Partners qualifications.
Company Number: 07865143 | Company VAT: 177073296